
用栈实现队列/用队列实现栈
队列是一种先进先出的数据结构,栈是一种先进后出的数据结构。
队列是一种先进先出的数据结构,栈是一种先进后出的数据结构,形象一点就是这样:
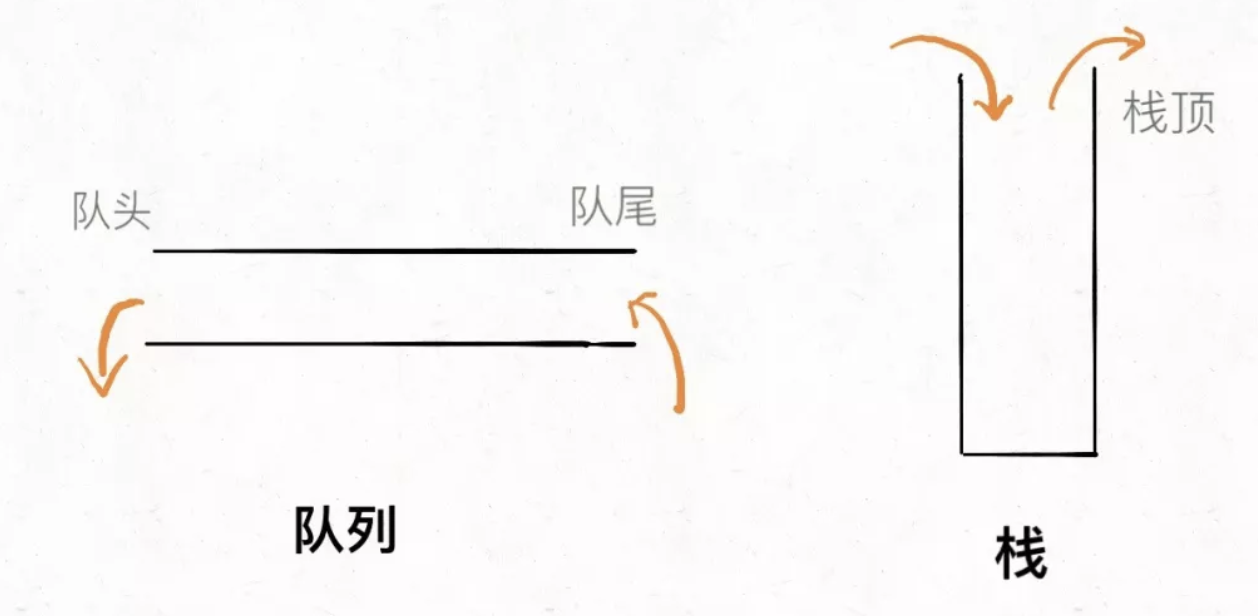
这两种数据结构底层其实都是数组或者链表实现的,只是 API 限定了它们的特性,那么今天就来看看如何使用「栈」的特性来实现一个「队列」,如何用「队列」实现一个「栈」。
用栈实现队列
首先,队列的 API 如下:
1 | class MyQueue { |
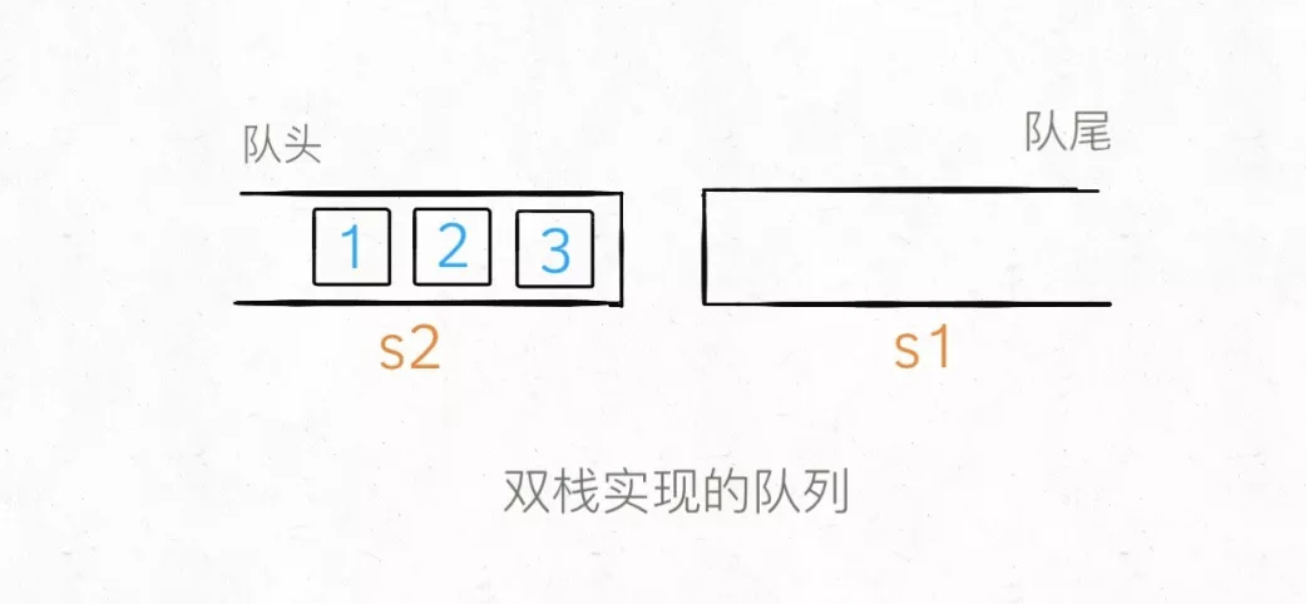
我们使用两个栈s1, s2就能实现一个队列的功能(这样放置栈可能更容易理解):
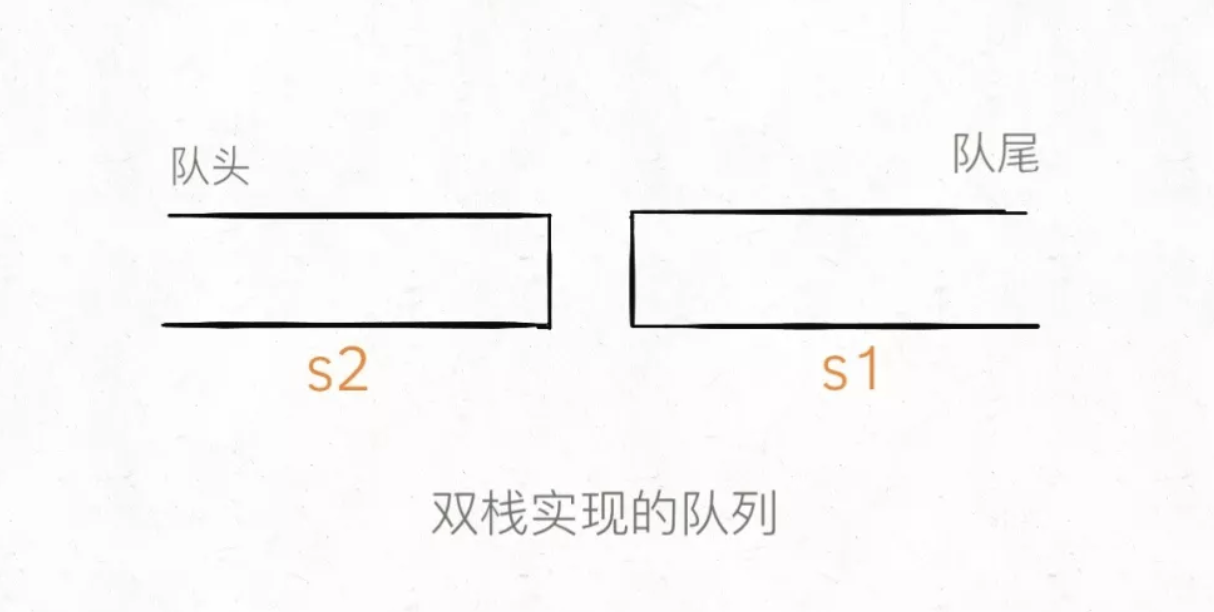
1 | class MyQueue { |
当调用push让元素入队时,只要把元素压入s1即可,比如说push进 3 个元素分别是 1,2,3,那么底层结构就是这样:
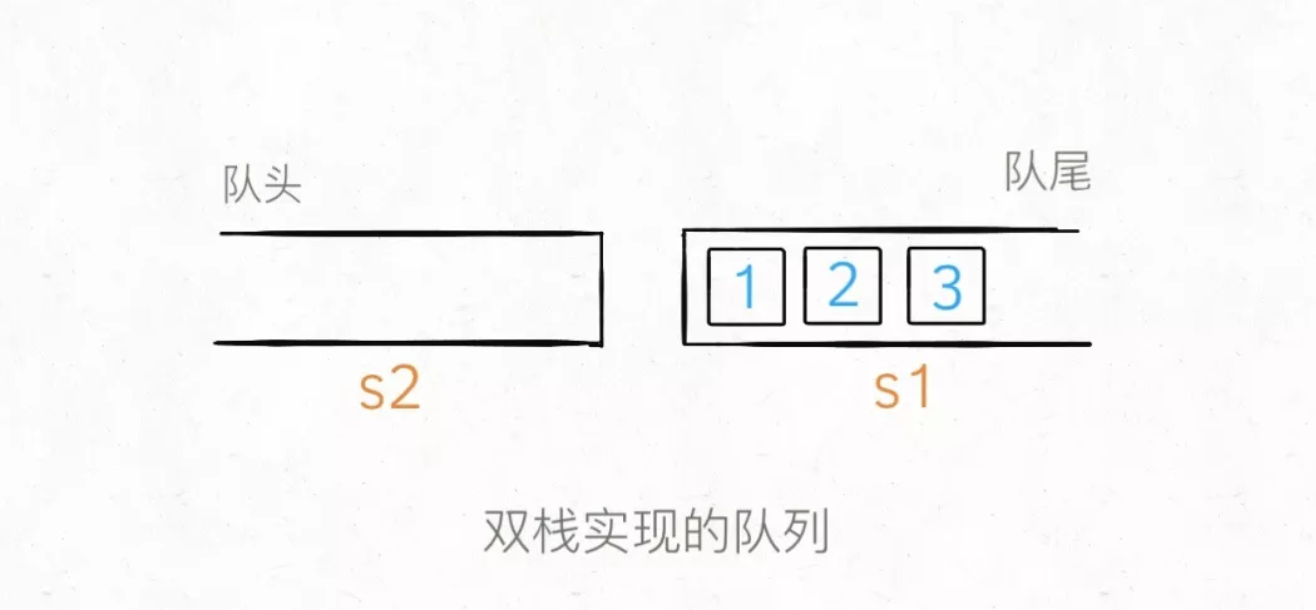
1 | /** 添加元素到队尾 */ |
那么如果这时候使用peek查看队头的元素怎么办呢?按道理队头元素应该是 1,但是在s1中 1 被压在栈底,现在就要轮到s2起到一个中转的作用了:
当s2为空时,可以把s1的所有元素取出再添加进s2,这时候s2中元素就是先进先出顺序了。
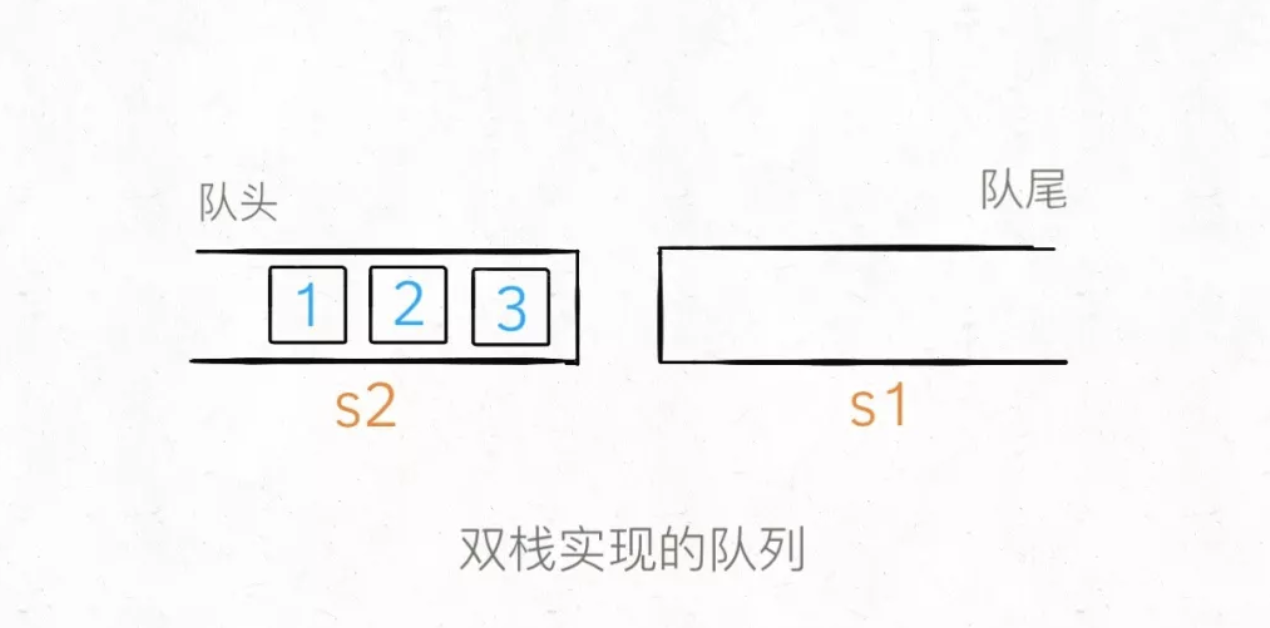
1 | /** 返回队头元素 */ |
同理,对于pop操作,只要操作s2就可以了。
1 | /** 删除队头的元素并返回 */ |
最后,如何判断队列是否为空呢?如果两个栈都为空的话,就说明队列为空:
1 | /** 判断队列是否为空 */ |
至此,就用栈结构实现了一个队列,核心思想是利用两个栈互相配合。
值得一提的是,这几个操作的时间复杂度是多少呢?其他操作都是 O(1),有点意思的是peek操作,调用它时可能触发while循环,这样的话时间复杂度是 O(N),但是大部分情况下while循环不会被触发,时间复杂度是 O(1)。由于pop操作调用了peek,它的时间复杂度和peek相同。
像这种情况,可以说它们的最坏时间复杂度是 O(N),因为包含while循环,可能需要从s1往s2搬移元素。
但是它们的均摊时间复杂度是 O(1),这个要这么理解:对于一个元素,最多只可能被搬运一次,也就是说peek操作平均到每个元素的时间复杂度是 O(1)。
用队列实现栈
如果说双栈实现队列比较巧妙,那么用队列实现栈就比较简单粗暴了,只需要一个队列作为底层数据结构。首先看下栈的 API:
1 | class MyStack { |
先说pushAPI,直接将元素加入队列,同时记录队尾元素,因为队尾元素相当于栈顶元素,如果要top查看栈顶元素的话可以直接返回:
1 | class MyStack { |
我们的底层数据结构是先进先出的队列,每次pop只能从队头取元素;但是栈是后进先出,也就是说popAPI 要从队尾取元素。
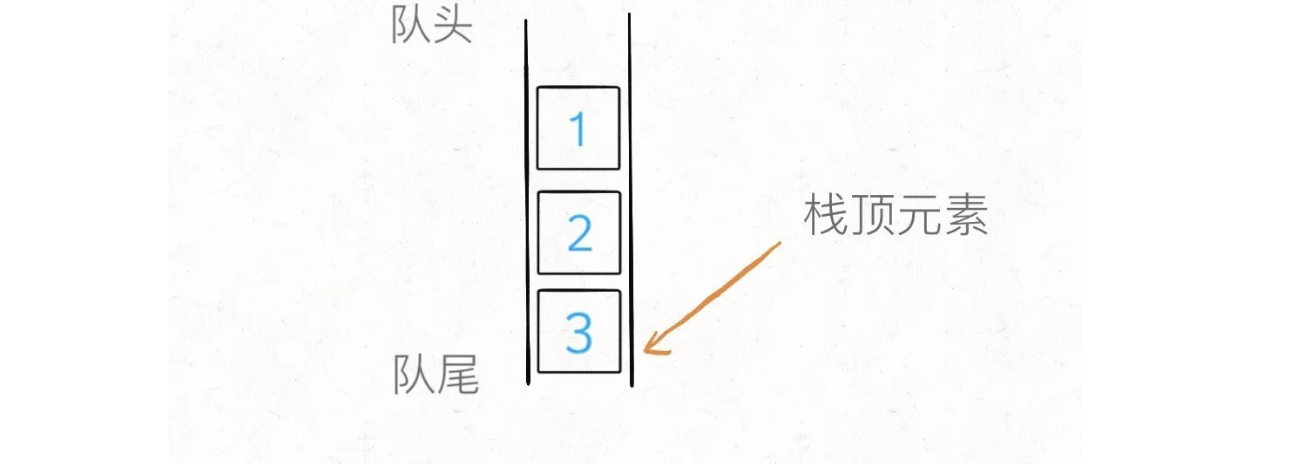
解决方法简单粗暴,把队列前面的都取出来再加入队尾,让之前的队尾元素排到队头,这样就可以取出了:
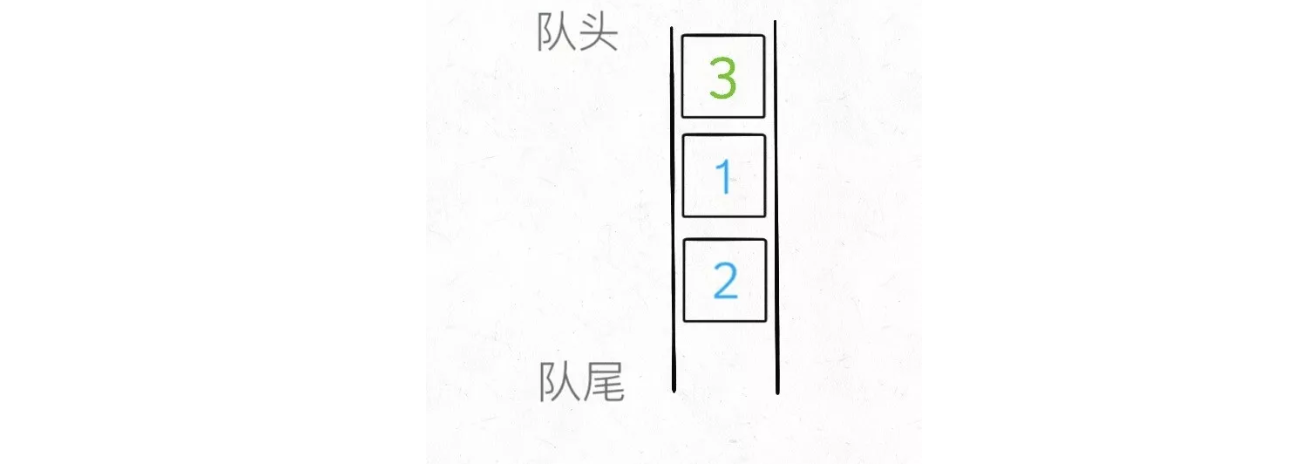
1 | /** 删除栈顶的元素并返回 */ |
这样实现还有一点小问题就是,原来的队尾元素被提到队头并删除了,但是top_elem变量没有更新,我们还需要一点小修改:
1 | /** 删除栈顶的元素并返回 */ |
最后,APIempty就很容易实现了,只要看底层的队列是否为空即可:
1 | /** 判断栈是否为空 */ |
很明显,用队列实现栈的话,pop 操作时间复杂度是 O(N),其他操作都是 O(1)。
个人认为,用队列实现栈没啥亮点,但是用双栈实现队列是值得学习的。
出栈顺序本来就和入栈顺序相反,但是从栈s1搬运元素到s2之后,s2中元素出栈的顺序就变成了队列的先进先出顺序,这个特性有点类似「负负得正」,确实不容易想到。
参考文章:
参考链接1





